포크/조인 프레임워크(Fork/Join Framework)란?
포크/조인 프레임워크는 병렬화할 수 있는 작업을 재귀적으로 작은 작업으로 분할한 다음에 서브태스크 각각의 결과를 합쳐서 전체 결과를 만들도록 설계되었다. 따라서 하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 준다.
이 알고리즘은 분할 후 정복(divide-and-conquer) 알고리즘의 병렬화 버전이다.
포크/조인 프레임워크에서는 서브태스크를 스레드 풀(ForkJoinPool)의 작업자 스레드에 분산 할당하는 ExecutorService 인터페이스를 구현한다.
RecursiveTask 활용
스레드 풀을 이용하려면 RecursiveTask<R>의 서브클래스를 만들어야 한다.
여기서 R은 병렬화된 태스크가 생성하는 결과 형식 또는 결과가 없을 때는 RecursiveAction 형식이다.
RecursiveTask를 정의하려면 추상 메서드 compute를 구현해야 한다.
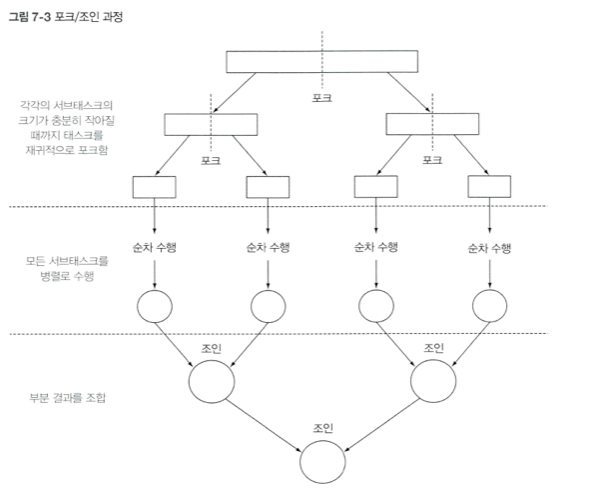
protected abstract R compute();compute 메서드는 태스크를 서브태스트로 분할하는 로직과 더 이상 분할할 수 없을 때 개별 서브태스크의 결과를 생산할 알고리즘을 정의한다. 따라서 대부분의 compute 메서드 구현은 다음과 같은 형식을 유지한다.
if (태스크가 충분히 작거나 더 이상 분할할 수 없으면) {
순차적으로 태스크 계산(알고리즘)
} else {
태스크를 두 서브태스크로 분할(재귀적 호출, Fork)
모든 서브태스크의 연산이 완료될 때까지 기다림
각 서브태스크의 결과를 합칩(Join)
}
그럼 주어진 숫자 배열의 요소값들을 모두 더하는 함수를 포크/조인 프레임워크를 사용해서 구현해보자.
public class SumCalculator extends RecursiveTask<Long> {
private final long[] numbers; // 더할 숫자 배열
private final int start; // 배열 초기 위치
private final int end; // 배열 최종 위치
private static final long THRESHOLD = 10; // 서브태스크 분할 최소 기준값
// 해당 클래스를 생성할때 사용할 공개 생성자
public SumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
// 재귀 호출을 위한 비공개 생성자
private SumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 이 태스크에서 처리할 길이
int length = end - start;
// 최소 기준값 이하 시 결과 계산
if (length <= THRESHOLD) return computeSequentially();
// 배열 길이의 반
int halfLength = start + length / 2;
// 배열의 길이를 절반으로 나누어 태스크로 분할
System.out.println("재귀 분할!");
// 왼쪽 태스크
SumCalculator leftTask = new SumCalculator(numbers, start, halfLength);
leftTask.fork(); // 왼쪽 태스크는 다른 스레드로 태스크를 비동기로 실행
// 오른쪽 태스크
SumCalculator rightTask = new SumCalculator(numbers, halfLength, end);
Long rightResult = rightTask.compute(); // 오른쪽 태스크는 재귀함수 호출
Long leftResult = leftTask.join(); // 왼쪽 태스크의 결과를 읽거나 아직 결과가 없으면 기다림
return leftResult + rightResult; // 왼쪽 태스크 결과 + 오른쪽 태스크 결과
}
private long computeSequentially() {
System.out.println("숫자 더하기!");
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}위 코드를 보면 설명한 형식과 동일하게 일정 사이즈까지 재귀적으로 포크 후 조인하여 결과를 도출한다.
사용할때는 ForkJoinPool의 invoke 메서드로 전달한다.
분할과 결과 도출을 쉽게 확인하기 위해 1부터 20까지 숫자의 합을 구해보자.
long[] numbers = LongStream.rangeClosed(1, 20).toArray();
SumCalculator task = new SumCalculator(numbers);
Long result = new ForkJoinPool().invoke(task);
System.out.println("결과 : " + result);THRESHOLD를 10으로 설정했기 때문에 분할은 한번만 될 것이고 분할된 각각의 스레드에서 숫자를 더해 결과를 도출할 것이다.

실행 결과를 확인해보면 정상적으로 출력된 것을 확인할 수 있다.
하지만 병렬 스트림을 이용할 때보다 성능이 더 좋지 않을 것이다. 전체 스트림을 long[]으로 변환했기 때문이다.
일반적으로 애플리케이션에서는 둘 이상의 ForkJoinPool을 사용하지 않는다.
즉, 소프트웨어의 필요한 곳에서 언제든 가져다 쓸 수 있도록 ForkJoinPool을 한 번만 인스턴스화해서 정적 필드에 싱글턴으로 저장한다.
ForkJoinPool의 인스턴스를 생성하면서 인수가 없는 기본 생성자를 이용했는데, 이는 JVM에서 이용할 수 있는 모든 프로세서가 자유롭게 풀에 접근할 수 있음을 의미한다.
정확하게는 Runtime.availableProcessors의 반환값으로 풀에 사용할 스레드 수를 결정한다.
Runtime.availableProcessors의 반환값에는 하이퍼스레딩과 관련된 가상 프로세서도 개수에 포함이 된다.
포크/조인 프레임워크를 제대로 사용하는 방법
포크/조인 프레임워크는 쉽게 사용할 수 있는 편이지만 항상 주의를 기울여야 한다.
다음은 포크/조인 프레임워크를 효과적으로 사용하는 방법이다.
▶ 두 서브태스크가 모두 시작된 다음에 join을 호출해야 한다.
그렇지 않으면 각각의 서브태스크가 다른 태스크가 끄타길 기다리는 일이 발생하며 원래 순차 알고리즘보다 느리고 복잡한 프로그램이 되어버릴 수 있다.
▶ RecursiveTask 내에서는 ForkJoinPool의 invoke 메서드를 사용하지 말아야 한다.
대신 compute나 fork 메서드를 직접 호출할 수 있다. 순차 코드에서 병렬 계산을 시작할 때만 invoke를 사용한다.
▶ 서브태스크에 fork 메서드를 호출해서 ForkJoinPool의 일정을 조절할 수 있다.
양쪽 작업 모두 fork 메서드를 호출하는 것이 자연스러울 것 같지만 한쪽 작업에 fork를 호출하는 것 보다는 compute를 호출하는 것이 효율적이다. 그러면 두 서브 태스크의 한 태스크에는 같은 스레드를 재사용할 수 있으므로 풀에서 불필요한 태스크를 할당하는 오버헤드를 피할 수 있다.
▶ 포크/조인 프레임워크를 이용하는 병렬 계산은 디버깅하기 어렵다.
포크/조인 프레임워크에서는 fork라 불리는 다른 스레드에서 compute를 호출하므로 스택 트레이스가 도움이 되지 않는다.
▶ 포크/조인 프레임워크를 사용하는 것이 순차 처리보다 무조건 빠르지 않다.
각 서브태스크의 실행시간은 새로운 태스크를 포킹하는 데 드는 시간보다 길어야 포크/조인 프레임워크를 사용하는 것이 순차 처리보다 빠르다. 그러므로 상황에 맞게 결과를 측정하며 사용해야 한다.
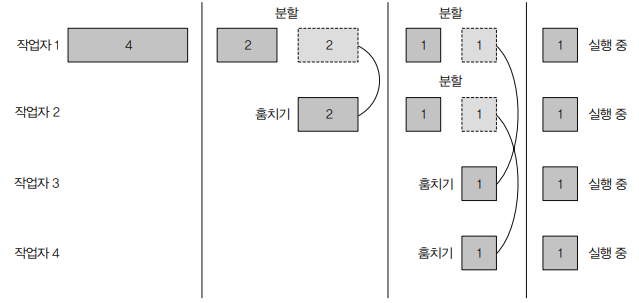
작업 훔치기(work stealing)
이론적으로는 코어 개수만큼 병렬화된 태스크로 작업부하를 분할하면 모든 CPU 코어에서 태스크를 실행할 것이고 크기가 같은 각각의 태스크는 같은 시간에 종료될 것이라 생각할 수 있다.
하지만 복잡한 시나리오가 사용되는 현실에서는 각각의 서브태스크의 작업완료 시간이 크게 달라질 수 있다.
분할 기법이 효율적이지 않았기 때문일 수도 있고 아니면 예기치 않게 디스크 접근 속도가 저하되었거나 외부 서비스와 협력하는 과정에서 지연이 생길 수 있기 때문이다.
포크/조인 프레임워크에서는 작업 훔치기(work stealing)라는 기법으로 이 문제를 해결한다.
작업 훔치기 기법에서는 ForkJoinPool의 모든 스레드를 거의 공정하게 분할한다.
각각의 스레드는 자신에게 할당된 태스크를 포함하는 이중 연결 리스트(doubly linked list)를 참조하면서 작업이 끝날 때마다 큐의 헤더에서 다른 태스크를 가져와서 작업을 처리한다.
즉, 다른 스레드는 바쁘게 일하고 있는데 한 스레드는 할일이 다 떨어진 상황에서 다른 스레드 큐의 꼬리에서 작업을 훔쳐온다. 따라서 스레드 간의 작업 부하를 비슷한 수준으로 유지할 수 있다.
'Java' 카테고리의 다른 글
| [모던 자바] 컬렉션 팩토리(Collection Factory) 소개 및 사용법 (0) | 2022.03.10 |
|---|---|
| [모던 자바] Spliterator 인터페이스란 무엇인가? (0) | 2022.03.10 |
| [모던 자바] 병렬 데이터 처리와 성능 측정 (1) | 2022.03.08 |
| [모던 자바] Collector 인터페이스 소개 및 구현 예제 (0) | 2022.03.08 |
| [모던 자바] 컬렉터(Collector)란 무엇인가? (0) | 2022.03.07 |