java7이 등장하기 전에는 데이터 컬렉션을 병렬로 처리하기가 어려웠다.
우선 데이터를 서브 파트로 분할해야 하고, 분할된 서브 파트를 각각의 스레드로 할당한다.
스레드로 할당한 다음에는 의도치 않은 레이스 컨디션이 발생하지 않도록 적절한 동기화를 추가해야 하며, 마지막으로 부분 결과를 합쳐야 한다.
java7은 더 쉽게 병렬화를 수행하면서 에러를 최소화할 수 이도록 포크/조인 프레임워크(fork/join framework) 기능을 제공한다.
이번에는 스트림으로 데이터 컬렉션 관련 동작을 얼마나 쉽게 병렬로 실행하는지 살펴보자.
스트림을 이용하면 순차 스트림을 병렬 스트림으로 자연스럽게 바꿀 수 있다.
병렬 스트림이 내부적으로 어떻게 처리되는지 알아야만 스트림을 잘못 사용하는 상황을 피할 수 있다.
병렬 스트림이란?
병렬 스트림이란 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다.
따라서 병렬 스트림을 이용하려면 모든 멀티코어 프로세서가 각각의 청크를 처리하도록 할당할 수 있다.
컬렉션에 parallelStream을 호출하면 병렬 스트림(parallel stream)이 생성된다.
예를 들어 숫자 n을 인수로 받아서 1부터 n까지 모든 숫자의 합계를 반환하는 메서드를 구현한다고 가정해보자.
public long numberSum(long n) {
return Stream.iterate(1L ,i -> i + 1)
.limit(n)
.reduce(0L, Long::sum);
}스트림을 사용해서 구현하면 다음과 같이 코드를 구현할 수 있다.
여기서 n이 커진다면 이 연산을 병렬로 처리하는 것이 좋을 것이다. 이럴 때 병렬 스트림을 사용하면 쉽게 병렬 처리를 할 수 있다.
순차 스트림을 병렬 스트림으로 변환하기
순차 스트림에 parallel 메서드를 호출하면 기존의 함수형 리듀싱 연산이 병렬로 처리된다.
public long numberSum(long n) {
return Stream.iterate(1L ,i -> i + 1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);
}이전 코드와 다른 점은 스트림이 여러 청크로 분할되어 있다는 것이다.
마지막으로 리듀싱 연산으로 생성된 부분 결과를 다시 리듀싱 연산으로 합쳐서 전체 스트림의 리듀싱 결과를 도출한다.
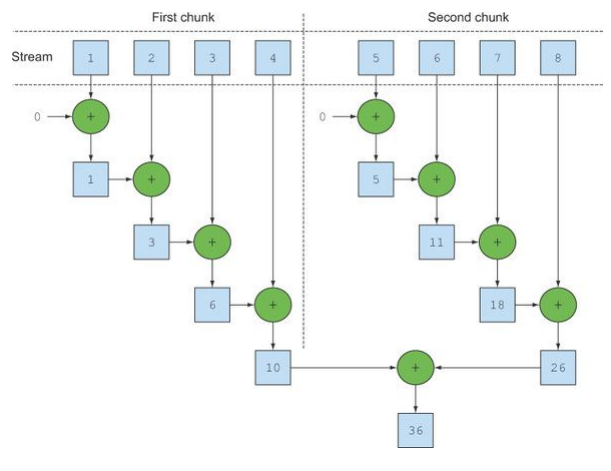
사실 순차 스트림에 parallel을 호출해도 스트림 자체에는 아무 변화도 일어나지 않고 연산이 병렬 처리 여부를 의미하는 블리언 플래그가 설정된다.
반대로 sequential로 병렬 스트림을 순차 스트림으로 바꿀 수 있다.
아래 코드처럼 두 메서드(parallel, sequential)를 이용해서 어떤 연산을 병렬로 실행하고 어떤 연산을 순차로 실행할지 제어할 수 있다.
만약 하나에 파이프라인에 두 메서드를 모두 사용한다면 두 메서드 중 최종적으로 호출된 메서드가 전체 파이프라인에 영향을 미친다.
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();위 코드는 parallel()이 마지막 호출됬으므로 이 파이프라인은 병렬로 실행된다.
병렬 스트림에서 사용하는 스레드 풀 설정
병렬 스트림은 내부적으로 ForkJoinPool을 사용한다.
기본적으로 ForkJoinPool은 프로세서 수. 즉, Runtime.getRuntime().availableProcessors()가 반환하는 값에 상응하는 스레드를 갖는다.
현재는 하나의 병렬 스트림에 사용할 수 있는 특정한 값을 지정할 수 없다.
일반적으로 기기의 프로세서 수와 같으므로 특별한 이유가 없다면 ForkJoinPool의 기본값을 그대로 사용하는 것을 권장한다.
스트림 성능 측정
병렬화를 이용하면 순차나 반복 형식에 비해 성능이 더 좋아질 것이라 추측했다.
성능을 최적화할 때는 무조건적으로 측정이 중요하다. 측정하지 않은 코드는 최적화했다고 할 수 없다.
자바 마이크로벤치마크 하니스(Java Microbenchmark Harness, JMH)라는 라이브러리를 이용해 간단하게 자바 코드의 성능을 측정해보자.
아래 설정은 gradle 기준으로 정리했다.
프로젝트 설정
jmh-gradle-plugin를 사용할 것인데 프로젝트 gradle에 따라 지원하는 버전이 다르다.
JMH gradle plugin github에 접속해보면 그래들 버전에 맞는 플러그인 버전을 확인할 수 있다.
2022-03-08 기준으로 인텔리제이에서 생성한 프로젝트는 gradle 7.4를 사용하고 있어서 0.6.6(버전 0.6 이상은 Gradle 6.8 이상이 필요)으로 설정해보겠다.
build.gradle에 plugin을 추가하고 dependencies에 필요한 의존성을 추가하였다.
JMH의 최신 LTS는 1.29를 지원하고 있다.
0.6.0 이전 버전의 플러그인은 id를 me.champeau.gradle.jmh로 작성해야 한다.
plugins {
...
id "me.champeau.jmh" version "0.6.6"
}
...
dependencies {
jmh 'org.openjdk.jmh:jmh-core:1.29'
jmh 'org.openjdk.jmh:jmh-generator-annprocess:1.29'
....
}코드 작성
이제 벤치마킹할 코드를 작성해야 하는데 src/jmh/java 패키지를 생성하고 그 하위에 패키지를 더 만들어야 한다.
하위에 패키지를 만들지 않고 바로 클래스 파일을 2개 이상 생성하게 되면 에러가 발생한다.
나는 src/jmh/java 하위에 benchmark라는 패키지를 만들어 그 안에 클래스를 생성하였다.
그럼 1부터 n까지 모든 숫자의 합계를 반환하는 메서드를 Stream을 사용하지 않고 구현하는 메서드와 사용하고 구현한 메서드를 벤치 마크하는 ParallelStreamBenchmark 클래스를 생성해보자.
@State(Scope.Benchmark) // 동일 테스트 내 모든 Thread에서 동일 Instance를 공유 (Multi-Threading 테스트)
@BenchmarkMode(Mode.AverageTime) // 벤치마크 대상 메서드를 실행하는 데 걸린 평균 시간 측정
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 벤치마크 결과를 밀리초 단위로 출력
@Fork(value = 2, jvmArgs = {"-Xms4G", "-Xmx4G"}) // 4GB의 힙 공간을 제공한 환경에서 두 번 벤치마크를 수행해 결과의 신뢰성 확보
public class ParallelStreamBenchmark {
private static final long N = 10_000_000L;
@Benchmark // 벤치마크 대상 메서드
public long numberSum() { // for문 사용
long result = 0;
for (long i = 1L; i <= N; i++) {
result += i;
}
return result;
}
@Benchmark
public long streamNumberSum() { // Stream.iterate 사용
return Stream.iterate(1L, i -> i + 1)
.limit(N)
.reduce(0L, Long::sum);
}
@Benchmark
public long streamParallelNumberSum() { // Stream.iterate 사용, 병렬처리
return Stream.iterate(1L, i -> i + 1)
.limit(N)
.parallel()
.reduce(0L, Long::sum);
}
@TearDown(Level.Invocation) // 매 번 베치마크를 실행한 다음에는 가비지 컬렉터 동작 시도
public void tearDown() {
System.gc();
}
}벤치마크가 가능한 가비지 컬렉터의 영향을 받지 않도록 힙의 크기를 충분하게 설정했을 뿐 아니라 벤치마크가 끝날 때마다 가비지 컬렉터가 실행되도록 강제했다.
하지만 기계가 지원하는 코어의 개수 등이 실행 시간에 영향을 미칠 수 있기 때문에 결과는 정확하지 않을 수 있다.
코드 실행
그럼 터미널에서 아래 명령어를 실행시켜 벤치마크를 실행해보자.
$ ./gradlew jmh
실행 결과는 콘솔에도 출력되지만 build/results/jmh/results.txt에서 확인할 수 있다.
확인 결과 for문 -> Stream.iterate -> Stream.iterate 병렬 처리 순으로 빠른 것을 확인할 수 있다.
for문을 사용해 반복적인 방법이 더 저수준으로 동작할 뿐 아니라 특히 기본값을 박싱 하거나 언박싱할 필요가 없으므로 가장 빠를 것이다.
하지만 순차 연산보다 병렬 연산이 더 느린 이유가 무엇일까?
- 반복 결과로 박싱 된 객체가 만들어지므로 숫자를 더하려면 언박싱을 해야 한다.
- 반복 작업은 병렬로 수행할 수 있는 독립 단위로 나누기가 어렵다.
우리는 병렬 처리를 했지만 리듀싱 과정을 시작하는 시점에서 전체 숫자 리스트가 준비되지 않았으므로 스트림을 병렬로 처리할 수 있도록 청크로 분할할 수 없다. 그 결과 스레드를 할당하는 오버헤드만 증가하게 된다.
이번엔 LongStream라는 더 특화된 메서드를 사용해서 벤치마크를 해볼 것이다.
@Benchmark
public long longStreamNumberSum() { // LongStream.rangeClosed 사용
return LongStream.rangeClosed(1L, N)
.reduce(0L, Long::sum);
}
@Benchmark
public long longStreamParallelNumberSum() { // LongStream.rangeClosed 사용, 병렬 처리
return LongStream.rangeClosed(1L, N)
.parallel()
.reduce(0L, Long::sum);
}
기존의 iterate 메서드로 생성한 순차 연산에 비해 스트림 처리 속도가 더 빠른 것을 확인할 수 있다.
iterate 메서드를 사용해 처리할 때는 오토 박싱, 언박싱 등의 오버 헤드를 수반하기 때문이다.
LongStream에 병렬 처리를 한 것도 일반 Stream에 비해 빠른 것을 확인할 수 있다.
상황에 따라서 어떤 알고리즘을 병렬화하는 것보다 적절한 자료구조를 선택하는 것이 더 중요하다는 사실을 알 수 있다.
병렬화가 완전 공짜는 아니라는 사실을 기억하자.
병렬화를 이용하려면 스트림을 재귀적으로 분할해야 하고, 각 서브 스트림을 서로 다른 스레드의 리듀싱 연산으로 할당하고, 이들 결과를 하나의 값으로 합쳐야 한다.
멀티코어 간의 데이터 이동은 우리 생각보다 비싸다. 따라서 코어 간에 데이터 전송 시간보다 훨씬 오래 걸리는 작업만 병렬로 다른 코어에서 수행하는 것이 바람직하다.
이처럼 병렬 프로그래밍은 까다롭고 때로는 이해하기 어려운 함정이 숨어있다.
병렬 스트림의 올바른 사용법
병렬 스트림을 잘못 사용하면서 발생하는 많은 문제는 공유된 상태를 바꾸는 알고리즘을 사용하기 때문이다.
public class AddNumber {
private long total = 0;
private void add(long value) {
total += value;
}
}
public long sideEffectAddNumber(long n) {
AddNumber addNumber = new AddNumber();
LongStream.rangeClosed(1, n).parallel().forEach(addNumber::add);
return addNumber.getTotal();
}만약 위와 같은 코드가 있다고 가정해보자.
병렬 처리를 했기 때문에 여러 스레드에서 addNumber.total 값에 접근하기 때문에 결과 값이 달라지고, 성능도 좋지 않다.
병렬 스트림과 병렬 계산에서는 공유된 가변 상태를 피해야 한다.
그럼 어떤 상황에 병렬 스트림을 사용해야 할까?
"만 개 이상으로 요소가 있을 때만 병렬 스트림을 사용해라"와 같이 양을 기준으로 병렬 스트림을 사용하는 것은 적절하지 않다. 물론 정해진 기기와 정해진 연산을 수행할 때는 이와 같은 기준이 도움이 될 수 있지만 상황이 달라지면 이와 같은 기준은 제 역할을 하지 못한다.
아래와 같은 기준으로 병렬 스트림을 사용한다면 도움이 될 것이다.
- 확신이 서지 않으면 직접 측정해라.
- 박싱(자동 박싱, 언박싱)을 주의하라.
- 스트림이 순서에 의존한다면, 병렬 스트림보다 순차 스트림의 성능이 좋다.
- 스트림에서 수행하는 전체 파이프라인 연산 비용을 고려하라.
(각 스트림에 요소 처리 비용이 높다면 병렬 스트림으로 성능을 개선할 수 있다.) - 소량의 데이터에서는 병렬 스트림이 도움 되지 않는다.
- 스트림을 구성하는 자료구조가 적절한지 확인하라.
(Stream.iterate -> LongStream.rangeClosed) - 스트림의 특성과 파이프라인의 중간 연산이 스트림의 특성을 어떻게 바꾸는지에 따라 성능이 달라질 수 있다.
(길이가 예측되는 스트림은 병렬 처리로 성능을 개선할 수 있다.) - 최종 연산의 병합 과정 비용을 확인하라.
(병합 과정의 비용이 비싸다면 병렬 스트림으로 얻은 성능의 이익이 상쇄될 수 있다.)
스트림에 대해 잘 모르다가 이번 공부를 하며 조금 알게 되었는데 정말 쓸모가 많은 친구라는 걸 알게 되었지만 그만큼 적절한 상황에 사용하는 건 어려운 것 같다... 직접 측정해보고 확인해보며 많은 경험을 얻어야 할 것 같다.
'Java' 카테고리의 다른 글
| [모던 자바] Spliterator 인터페이스란 무엇인가? (0) | 2022.03.10 |
|---|---|
| [모던 자바] 포크/조인 프레임워크란 무엇인가? (0) | 2022.03.10 |
| [모던 자바] Collector 인터페이스 소개 및 구현 예제 (0) | 2022.03.08 |
| [모던 자바] 컬렉터(Collector)란 무엇인가? (0) | 2022.03.07 |
| [모던 자바] 스트림(Stream) 만들기 (0) | 2022.03.04 |