Filebeat는 로그 데이터를 전달하고 중앙화하기 위한 경량의 Producer이다.
Filebeat는 지정한 로그 파일 또는 위치를 모니터링하고 로그 이벤트를 수집해 Logstash로 전달해주고, 가공 작업을 거쳐 Elasticsearch로 보내주고 이 결과를 Kibana로 볼 수 있도록 구축할 예정이다.
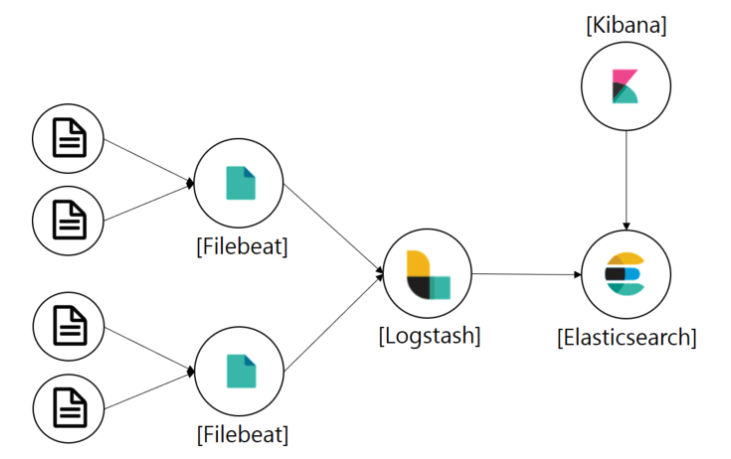
1. Application 로그 수집
먼저 Spring Boot Application에서 로그를 수집해야 한다.
나의 경우는 AOP와 Logback을 통해 API 로그와 오류 로그만 수집하도록 설정하였다.
1-1. AOP 설정
LoggingAspect.java
@Aspect
@Component
@RequiredArgsConstructor
public class LoggingAspect {
private static final Logger logger = LoggerFactory.getLogger(LoggingAspect.class);
private final ObjectMapper objectMapper;
// 모든 컨트롤러 && NotLogging 어노테이션 미설정 시 로그 수집
@Pointcut("within(*..*Controller) && !@annotation(com.project.sample.aop.NotLogging)")
public void onRequest() {}
@Around("onRequest()")
public Object requestLogging(ProceedingJoinPoint joinPoint) throws Throwable {
// API 요청 정보
final RequestApiInfo apiInfo = new RequestApiInfo(joinPoint, joinPoint.getTarget().getClass(), objectMapper);
// 로그 정보
final LogInfo logInfo = new LogInfo(
apiInfo.getUrl(),
apiInfo.getName(),
apiInfo.getMethod(),
apiInfo.getHeader(),
objectMapper.writeValueAsString(apiInfo.getParameters()),
objectMapper.writeValueAsString(apiInfo.getBody()),
apiInfo.getIpAddress(),
apiInfo.getUserId(),
apiInfo.getUserName()
);
try {
final Object result = joinPoint.proceed(joinPoint.getArgs());
// Method가 Get이 아닌 로그만 수집
if (!logInfo.getMethod().equals("GET")) {
final String logMessage = objectMapper.writeValueAsString(Map.entry("logInfo", logInfo));
logger.info(logMessage);
}
return result;
} catch (Exception e) {
final StringWriter sw = new StringWriter();
e.printStackTrace(new PrintWriter(sw));
final String exceptionAsString = sw.toString();
// 발생 Exception 설정
logInfo.setException(exceptionAsString);
final String logMessage = objectMapper.writeValueAsString(logInfo);
logger.error(logMessage);
throw e;
}
}
}
1-2. logback 설정
application.yml
logging:
config: classpath:logback-spring.xml
...logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 콘솔 로깅 -->
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%d{yyyy-MM-dd HH:mm:ss}][%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<property name="LOG_PATH" value="./logs"/>
<property name="LOG_FILE_NAME" value="api"/>
<property name="ERR_LOG_FILE_NAME" value="api-error"/>
<!-- API 로깅 -->
<appender name="ApiLogFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<file>${LOG_PATH}/${LOG_FILE_NAME}.log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%msg%n</pattern>
</encoder>
<!-- 하루에 한번 압축 후 보관, 최대 30일, 1GB까지 보관 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/${LOG_FILE_NAME}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
</appender>
<!-- 오류 로깅 -->
<appender name="ErrorLogFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<file>${LOG_PATH}/${ERR_LOG_FILE_NAME}.log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%msg%n</pattern>
</encoder>
<!-- 하루에 한번 압축 후 보관, 최대 30일, 1GB까지 보관 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/${ERR_LOG_FILE_NAME}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
</appender>
<springProfile name="local">
<logger name="com.spring.sample.aop.LoggingAspect" level="INFO">
<appender-ref ref="Console" />
<appender-ref ref="ApiLogFile" />
<appender-ref ref="ErrorLogFile" />
</logger>
</springProfile>
<springProfile name="dev">
<logger name="com.spring.sample.aop.LoggingAspect" level="INFO">
<appender-ref ref="ApiLogFile" />
<appender-ref ref="ErrorLogFile" />
</logger>
</springProfile>
<springProfile name="prod">
<logger name="com.spring.sample.aop.LoggingAspect" level="INFO">
<appender-ref ref="ApiLogFile" />
<appender-ref ref="ErrorLogFile" />
</logger>
</springProfile>
</configuration>위처럼 logback을 설정하면 API 요청 시 로그가 수집되는 것을 확인할 수 있다.


2. Docker로 ELK 설치 및 설정
https://github.com/deviantony/docker-elk 리포지토리를 사용하여 ELK를 설치해보자.
$ git clone https://github.com/deviantony/docker-elk.git
2-1. 환경변수 설정
설정 파일들을 살펴보면 환경변수로 비밀번호를 설정한 것을 확인할 수 있다.
.env 파일을 수정해 비밀번호를 설정해주자.
$ cd docker-elk
$ sudo vim .env.env
## Passwords for stack users
#
# User 'elastic' (built-in)
#
# Superuser role, full access to cluster management and data indices.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-users.html
ELASTIC_PASSWORD='1234'
# User 'logstash_internal' (custom)
#
# The user Logstash uses to connect and send data to Elasticsearch.
# https://www.elastic.co/guide/en/logstash/current/ls-security.html
LOGSTASH_INTERNAL_PASSWORD='1234'
# User 'kibana_system' (built-in)
#
# The user Kibana uses to connect and communicate with Elasticsearch.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-users.html
KIBANA_SYSTEM_PASSWORD='1234'
# Users 'metricbeat_internal', 'filebeat_internal' and 'heartbeat_internal' (custom)
#
# The users Beats use to connect and send data to Elasticsearch.
# https://www.elastic.co/guide/en/beats/metricbeat/current/feature-roles.html
METRICBEAT_INTERNAL_PASSWORD=''
FILEBEAT_INTERNAL_PASSWORD=''
HEARTBEAT_INTERNAL_PASSWORD=''
# User 'monitoring_internal' (custom)
#
# The user Metricbeat uses to collect monitoring data from stack components.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/how-monitoring-works.html
MONITORING_INTERNAL_PASSWORD=''
# User 'beats_system' (built-in)
#
# The user the Beats use when storing monitoring information in Elasticsearch.
# https://www.elastic.co/guide/en/elasticsearch/reference/current/built-in-users.html
BEATS_SYSTEM_PASSWORD=''elastic, logstash, kibana의 비밀번호를 설정해주자.
2-2. Logstash 설정
Logstash에 필터를 설정해주자.
$ sudo vim logstash/pipeline/logstash.conflogstash.conf
input {
beats {
port => 5044
}
tcp {
port => 50000
}
}
filter {
# logInfo의 JSON 데이터를 각 필드로 넣어준다.
json {
source => "logInfo"
}
# 제거할 필드 설정
mutate {
remove_field => ["@version","agent","ecs","host","input","log","tags"]
}
}
## Add your filters / logstash plugins configuration here
output {
elasticsearch {
# filebeat에서 fields: index_name으로 넘어온 값을 인덱스로 전송
index => "%{[fields][index_name]}"
hosts => "elasticsearch:9200"
user => "logstash_internal"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
}
}
2-3. 컨테이너 실행
Logstash 설정이 끝났다면 docker compose를 통해 컨테이너를 실행해보자.
$ docker-compose build && docker-compose up -d
$ docker ps
도커 컨테이너가 정상적으로 실행되고 있다면 kibana(http://localhost:5601)에 접속해보자.
elastic 계정에 위에서 설정해준 비밀번호로 로그인이 가능하다.
위처럼 접속이 가능하다면 정상적으로 elk가 설치된 것이다.
3. Filebeat 설치 및 설정
3-1. filebeat 설치
linux의 경우는 darwin용 대신 linux용으로 다운 받으면 된다.
$ curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.1-darwin-x86_64.tar.gz
$ tar xzvf filebeat-8.5.1-darwin-x86_64.tar.gz
$ cd filebeat-8.5.1-darwin-x86_64.tar.gz
3-2. filebeat 설정
filebeat.yml
$ sudo vim filebeat.yml###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
# filestream is an input for collecting log messages from files.
- type: log
# Unique ID among all inputs, an ID is required.
id: api-log # API 로그
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Users/.../logs/api.log # 로그 파일 위치
fields:
index_name: "api-log" # 인덱스명
# 디코딩된 JSON은 출력 문서의 "json" 키 아래에 배치
json.keys_under_root: true
# keys_under_root 설정이 활성화되면 디코딩된 JSON 개체의 값이 충돌 시 Filebeat가 일반적으로 추가하는 필드를 덮어쓰기
json.overwrite_keys: true
# SON 언마샬링 오류가 발생하거나 a message_key가 구성에 정의되어 있지만 사용할 수 없는 경우 "error.message" 및 "error.type: json" 키를 추가
json.add_error_key: true
# 이 설정이 활성화되면 Filebeat는 디코딩된 JSON에서 재귀적으로 키를 제거하고 계층적 객체 구조로 확장
# 예) {"a.b.c": 123}는 {"a":{"b":{"c":123}}}
json.expand_keys: true
- type: log
# Unique ID among all inputs, an ID is required.
id: api-error-log # 에러 로그
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Users/.../logs/api-error.log # 로그 파일 위치
fields:
index_name: "api-error-log" # 인덱스명
# 디코딩된 JSON은 출력 문서의 "json" 키 아래에 배치
json.keys_under_root: true
# keys_under_root 설정이 활성화되면 디코딩된 JSON 개체의 값이 충돌 시 Filebeat가 일반적으로 추가하는 필드를 덮어쓰기
json.overwrite_keys: true
# SON 언마샬링 오류가 발생하거나 a message_key가 구성에 정의되어 있지만 사용할 수 없는 경우 "error.message" 및 "error.type: json" 키를 추가
json.add_error_key: true
# 이 설정이 활성화되면 Filebeat는 디코딩된 JSON에서 재귀적으로 키를 제거하고 계층적 객체 구조로 확장
# 예) {"a.b.c": 123}는 {"a":{"b":{"c":123}}}
json.expand_keys: true
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
# Line filtering happens after the parsers pipeline. If you would like to filter lines
# before parsers, use include_message parser.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#prospector.scanner.exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# ================================== General ===================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
# ================================= Dashboards =================================
# These settings control loading the sample dashboards to the Kibana index. Loading
# the dashboards is disabled by default and can be enabled either by setting the
# options here or by using the `setup` command.
#setup.dashboards.enabled: false
# The URL from where to download the dashboards archive. By default this URL
# has a value which is computed based on the Beat name and version. For released
# versions, this URL points to the dashboard archive on the artifacts.elastic.co
# website.
#setup.dashboards.url:
# =================================== Kibana ===================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
#host: "localhost:5601"
# Kibana Space ID
# ID of the Kibana Space into which the dashboards should be loaded. By default,
# the Default Space will be used.
#space.id:
# =============================== Elastic Cloud ================================
# These settings simplify using Filebeat with the Elastic Cloud (https://cloud.elastic.co/).
# The cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# You can find the `cloud.id` in the Elastic Cloud web UI.
#cloud.id:
# The cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. The format is `<user>:<pass>`.
#cloud.auth:
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# ================================== Logging ===================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publisher", "service".
#logging.selectors: ["*"]
# ============================= X-Pack Monitoring ==============================
# Filebeat can export internal metrics to a central Elasticsearch monitoring
# cluster. This requires xpack monitoring to be enabled in Elasticsearch. The
# reporting is disabled by default.
# Set to true to enable the monitoring reporter.
#monitoring.enabled: false
# Sets the UUID of the Elasticsearch cluster under which monitoring data for this
# Filebeat instance will appear in the Stack Monitoring UI. If output.elasticsearch
# is enabled, the UUID is derived from the Elasticsearch cluster referenced by output.elasticsearch.
#monitoring.cluster_uuid:
# Uncomment to send the metrics to Elasticsearch. Most settings from the
# Elasticsearch output are accepted here as well.
# Note that the settings should point to your Elasticsearch *monitoring* cluster.
# Any setting that is not set is automatically inherited from the Elasticsearch
# output configuration, so if you have the Elasticsearch output configured such
# that it is pointing to your Elasticsearch monitoring cluster, you can simply
# uncomment the following line.
#monitoring.elasticsearch:
# ============================== Instrumentation ===============================
# Instrumentation support for the filebeat.
#instrumentation:
# Set to true to enable instrumentation of filebeat.
#enabled: false
# Environment in which filebeat is running on (eg: staging, production, etc.)
#environment: ""
# APM Server hosts to report instrumentation results to.
#hosts:
# - http://localhost:8200
# API Key for the APM Server(s).
# If api_key is set then secret_token will be ignored.
#api_key:
# Secret token for the APM Server(s).
#secret_token:
# ================================= Migration ==================================
# This allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: true
3-2. filebeat 실행
$ sudo ./filebeat -e -c filebeat.yml4. 테스트
위 설정이 끝나고 ELK와 Filebeat가 실행 중인 상태에서 API를 요청하여 로그를 쌓아보자.

위 이미지처럼 파일에는 로그가 정상적으로 수집되었는데, Kibana에 접속해보니 인덱스가 생성되지 않아서 Logstash 로그를 보니 아래와 같은 오류가 발생하고 있었다.
:error=>{"type"=>"security_exception", "reason"=>"action [indices:admin/auto_create] is unauthorized for user [logstash_internal] with effective roles [logstash_writer] on indices [api-log], this action is granted by the index privileges [auto_configure,create_index,manage,all]"}
대충 logstash_writer 권한에 auto_configure, create_index, manage, all 인덱스 권한이 필요하다고 한다.
Stack Management > Roles > logstash_writer에 아래 인덱스와 권한을 설정해주자.

이제 Index Management에 들어가 보면 설정한 인덱스들이 정상적으로 나타난다.

이제 Kibana Data View를 생성하고 Discover 탭에서 로그를 확인해보자.
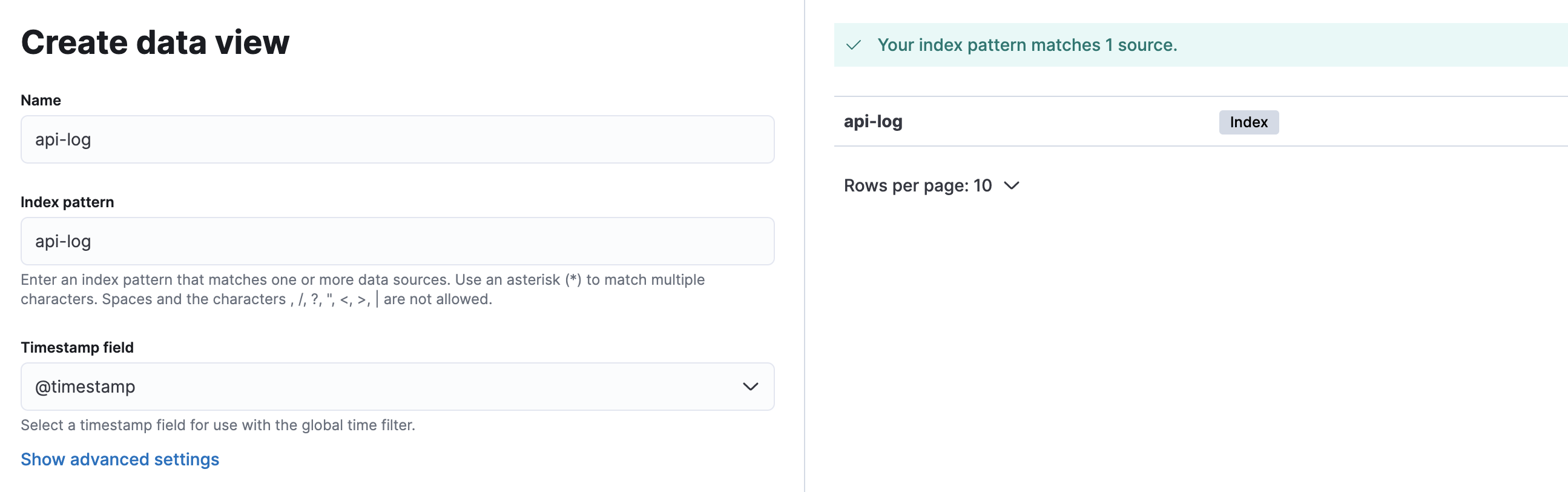
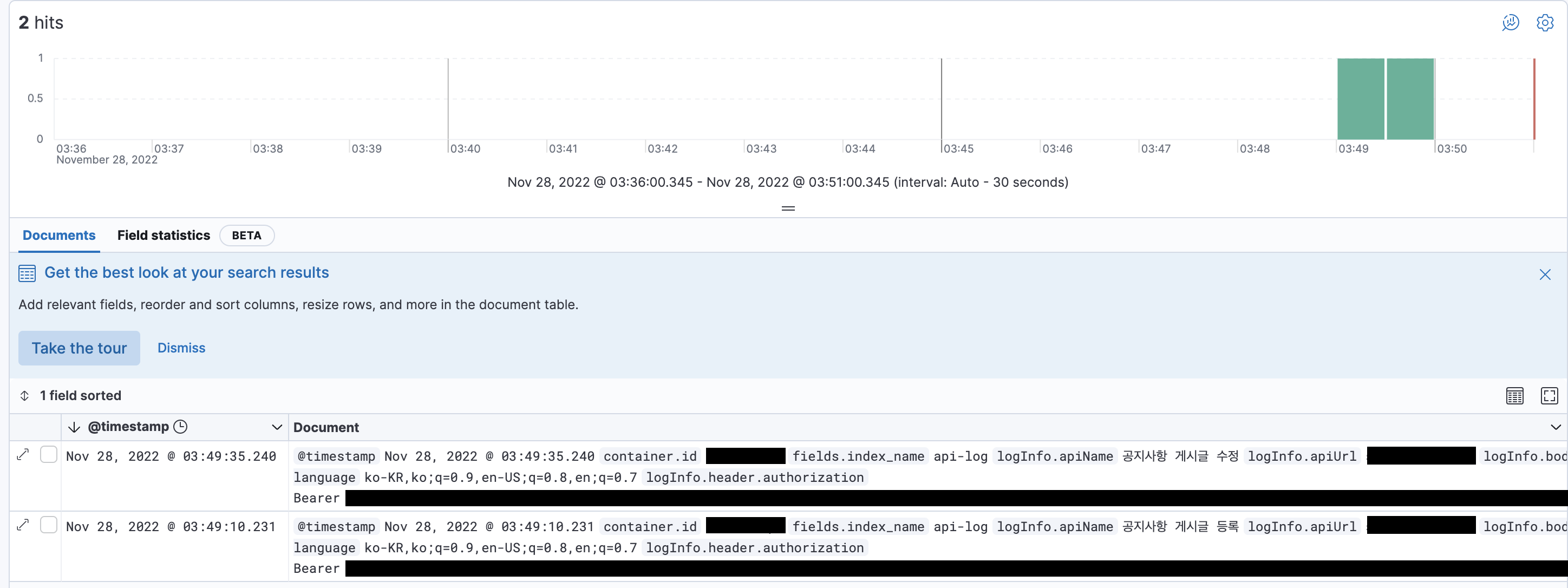
정상적으로 로그를 확인할 수 있다.
위 설명글은 매우 기본적인 설정들이라 ELK에 대해 더욱 알아보고 포스팅하도록 하겠습니다...
수정되어야 할 부분이나, 부족한 부분은 댓글 부탁드립니다!