[모던 자바] Spliterator 인터페이스란 무엇인가?
Spliterator 인터페이스란?
Spliterator는 분할할 수 있는 반복자라는 의미이다.
Iterator 처럼 Spliterator는 소스의 요소 탐색 기능을 제공한다는 점은 같지만 Spliterator는 병렬 작업에 특화되어 있다.
커스텀 Spliterator를 꼭 구현해야 하는 건 아니지만 Spliterator가 어떻게 동작하는지 이해한다면 병렬 스트림 동작과 관련한 통찰력을 얻을 수 있다.
java8은 컬렉션 프레임워크에 포함된 모든 자료구조에 사용할 수 있는 디폴트 Spliterator 구현을 제공한다.
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
...
}여기서 T는 Spliterator에서 탐색하는 요소의 형식을 가리킨다.
- tryAdvance : 요소를 하나씩 소비하면서 탐색해야 할 요소가 남아있으면 true 반환
- trySplit : 일부 요소를 분할해서 두 번째 Spliterator를 생성
- estimateSize : 탐색해야 할 요소의 수 제공
- characteristics : Spliterator 객체에 포함된 모든 특성값의 합을 반환
각 특성은 어떤 Spliterator 객체인가에 따라 다르며 그에 따른 각 메서드들의 내부적인 동작이 다를 수 있다.
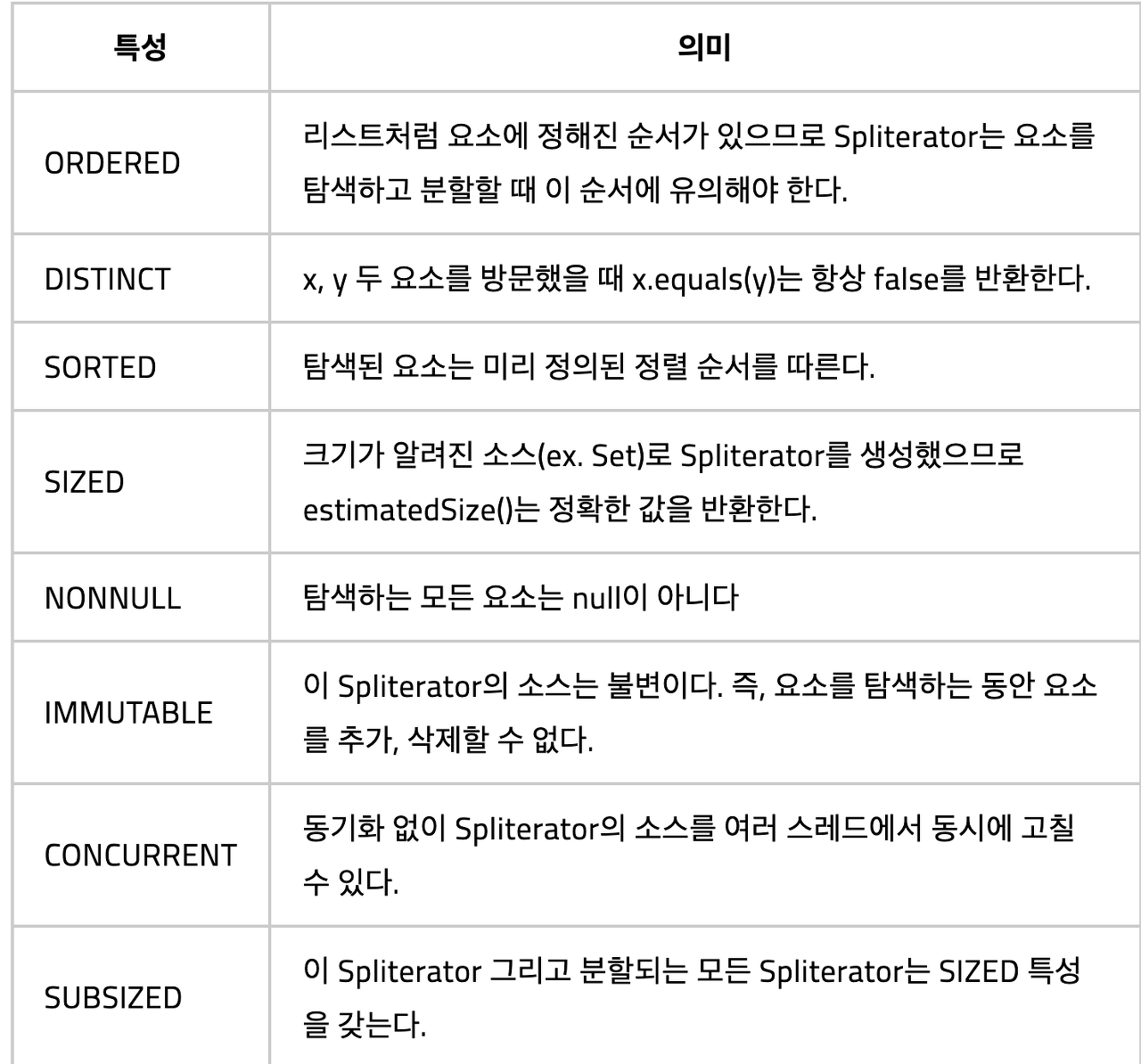
- List Spliterator : ORDERED, SIZED, SUBSIZED
- Set Spliterator : DISTINCT, SIZED
- IntStream.of Spliterator : IMMUTABLE, ORDERED, SIZED, SUBSIZED
- IntStream.generate Spliterator : IMMUTABLE
Spliterator 분할 과정
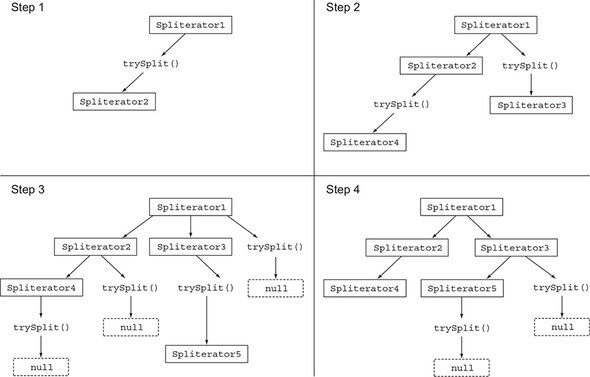
Step1. Spliterator에 trySplit를 호출해서 두 번째 Spliterator가 생성된다.
Step2. 두 개의 Spliterator에서 trySplit를 호출해 총 네개의 Spliterator가 생성된다.
Step3. trySplit이 null을 반환하면 더 이상 분할할 수 없다.
Step4. 모든 trySplit이 null을 반환하면 재귀 분할 과정이 종료 된다.
커스텀 Spliterator 구현하기
단순한 문자열의 단어 수를 계산하는 메서드를 구현해보자.
public int countWordsIteratively(String s) {
int counter = 0;
boolean lastSpace = true;
for (char c : s.toCharArray()) {
if (Character.isWhitespace(c)) {
lastSpace = true;
} else {
if (lastSpace) counter++;
lastSpace = false;
}
}
return counter;
}
final String sentence = "단순한 문자열의 단어 수를 계산하는 메서드를 구현해보자.";
int wordCount = countWordsIteratively(sentence);
System.out.println("wordCount : " + wordCount);
// 출력 결과 wordCount : 7위에서 작성한 반복형 대신 함수형을 이용하면 직접 스레드를 동기화하지 않고도 병렬 스트림으로 병렬화 할 수 있다.
public class WordCounter {
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter, boolean lastSpace) {
this.counter = counter;
this.lastSpace = lastSpace;
}
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c)) { // 공백 문자일때
// 앞 문자열이 공백이 아니면 lastSpace를 true로 변경
return lastSpace ? this : new WordCounter(counter, true);
} else { // 공백 문자가 아닐때
// 앞 문자열이 공백이면 counter + 1
return lastSpace ? new WordCounter(counter + 1, false) : this;
}
}
// 두 WordCounter의 counter값을 더한다.
public WordCounter combine(WordCounter wordCounter) {
return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace);
}
public int getCounter() {
return counter;
}
}
public int countWords(Stream<Character> stream) {
WordCounter wordCounter = stream
.reduce(new WordCounter(0 ,true), WordCounter::accumulate, WordCounter::combine);
return wordCounter.getCounter();
}
final String sentence = "단순한 문자열의 단어 수를 계산하는 메서드를 구현해보자.";
Stream<Character> stream = IntStream.range(0, sentence.length()).mapToObj(sentence::charAt);
int wordCount = countWords(stream);
System.out.println("wordCount : " + wordCount);
// 출력 결과 wordCount : 7코드를 보면 코드의 양이 꽤나 늘어났고 가독성이 좋아보이지 않는다.
하지만 코드를 이렇게 작성한 이유는 병렬 수행을 위해서다.
병렬로 수행하기
그렇다면 작성한 코드를 병렬로 실행해보자.
final String sentence = "단순한 문자열의 단어 수를 계산하는 메서드를 구현해보자.";
Stream<Character> stream = IntStream.range(0, sentence.length()).mapToObj(sentence::charAt);
int wordCount = countWords(stream.parallel());
System.out.println("wordCount : " + wordCount);
// 출력 결과 wordCount : 25병렬 처리만 했을 뿐인데 결과가 다르게 나타난다.
주어진 문자열을 청크로 분할할때 임의의 위치에서 둘로 나누다보니 예상치 못하게 하나의 단어를 둘로 계산하는 상황이 발생할 수 있다.
그렇다면 이 문제를 어떻게 해결해야 할까?
문자열을 임의의 위치에서 분할하지 말고 단어가 끝나는 위치에서만 분할하는 방법으로 이 문제를 해결할 수 있다.
이럴때 Spliterator를 사용하여 단어 끝에서 문자열을 분해해야 한다.
public class WordCounterSpliterator implements Spliterator<Character> {
private final String string;
private int currentChar = 0;
public WordCounter(String string) {
this.string = string;
}
// 탐색 할 요소가 남아있다면 true 반환
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
action.accept(string.charAt(currentChar++)); // 현재 문자열을 소비
return currentChar < string.length(); // 소비할 문자가 남아있으면 true 반환
}
// 요소를 분할해서 Spliterator 생성
@Override
public Spliterator<Character> trySplit() {
int currentSize = string.length() - currentChar;
if (currentSize < 10) return null;
// 파싱할 문자열의 중간을 분할 위치로 설정
for (int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++) {
if (Character.isWhitespace(string.charAt(splitPos))) { // 공백 문자가 나올때
// 문자열을 분할 해 Spliterator 생성
Spliterator<Character> spliterator = new WordCounter(string.substring(currentChar, splitPos));
// 시작을 분할 위치로 설정
currentChar = splitPos;
return spliterator;
}
}
return null;
}
// 탐색해야 할 요소의 수
@Override
public long estimateSize() {
return string.length() - currentChar;
}
// Spliterator 객체에 포함된 모든 특성값의 합을 반환
@Override
public int characteristics() {
// ORDERED : 문자열의 순서가 유의미함
// SIZED : estimatedSize 메서드의 반환값이 정확함
// NONNULL : 문자열에는 null이 존재하지 않음
// IMMUTABLE : 문자열 자체가 불변 클래스이므로 파싱하며 속성이 추가되지 않음
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}Spliterator를 구현하여 병렬 스트림을 생성한 뒤 다시 단어 수를 계산해보자.
final String sentence = "단순한 문자열의 단어 수를 계산하는 메서드를 구현해보자.";
Spliterator<Character> spliterator = new WordCounterSpliterator(sentence);
Stream<Character> stream = StreamSupport.stream(spliterator, true); // 병렬 스트림 생성
int wordCount = countWords(stream);
System.out.println("wordCount : " + wordCount);
// 출력 결과 wordCount : 7반복문과 마찬가지로 정상적인 결과가 출력된다.
Spliterator는 첫 번째 탐색 시점, 첫 번째 분할 시점, 또는 첫 번째 예상 크기(estimatedSize) 요청 시점에 요소의 소스를 바인딩할 수 있다.