Apache Kafka란?
Apache Kafka
Microservice Architecture는 개발 환경을 완전히 바꾸어 놓았다.
공유 데이터베이스 계층과 같은 종속성을 줄여 개발자들이 보다 민첩하게 작업을 수행하도록 해준다.
그러나 개발자가 구축 중인 분산형 애플리케이션이 데이터를 공유하려면 특정한 유형의 통합이 필요하다.
널리 사용되는 통합 옵션으로 동기식 방법이 있는데, 이는 서로 다른 사용자 간 데이터를 공유하는 데 애플리케이션 프로그래밍 인터페이스(Application Programming Interface, API)를 활용한다.
또 다른 통합 옵션으로는 중간 스토어에서 데이터를 복제하는 비동기식 방법이 있습니다.
Apache Kafka는 바로 이런 맥락에 등장하는 솔루션으로, 다른 개발팀의 데이터를 스트리밍하여 데이터 스토어를 채우면 해당 데이터를 여러 팀과 이들의 애플리케이션 간에 공유할 수 있는 분산 Application이다.
Kafka는 서버의 물리적 장애가 발생하는 경우에도 높은 가용성을 보장한다.
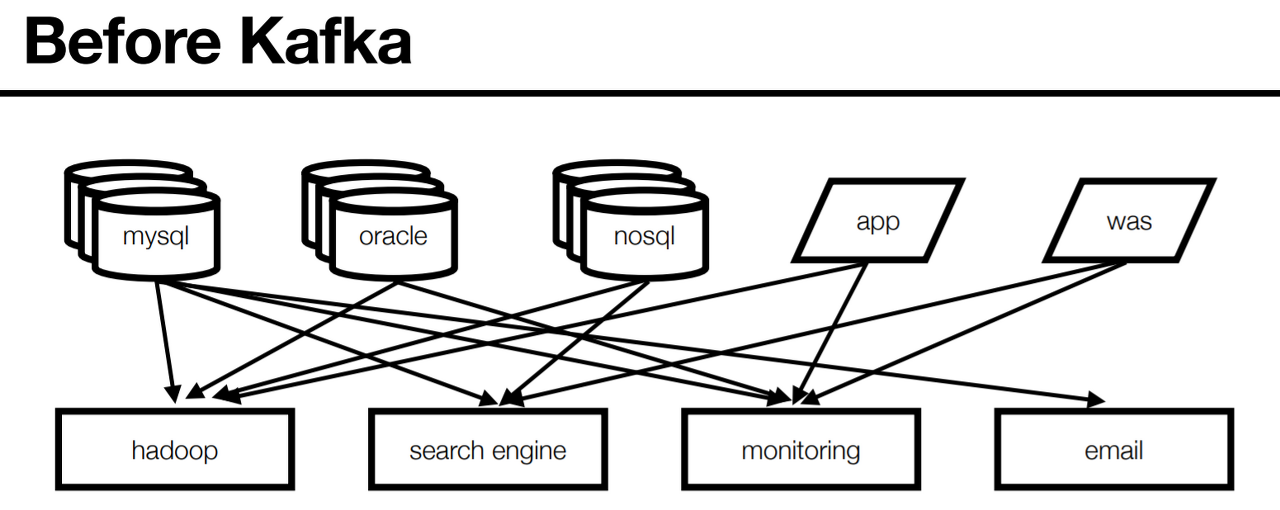
- 엔드투엔드(end-to-end) 연결 방식의 아키텍쳐
- 데이터 연동의 복잡성 증가(하드웨어, 운영체제, 장애 등)
- 각기 다른 데이터 파이프라인 연결 구조
- 확장에 엄청난 노력 필요
모든 시스템으로 데이터를 전송 실시간 처리도 가능해야 하고 데이터가 갑자기 많아지더라도 호가장이 용이한 시스템이 필요함
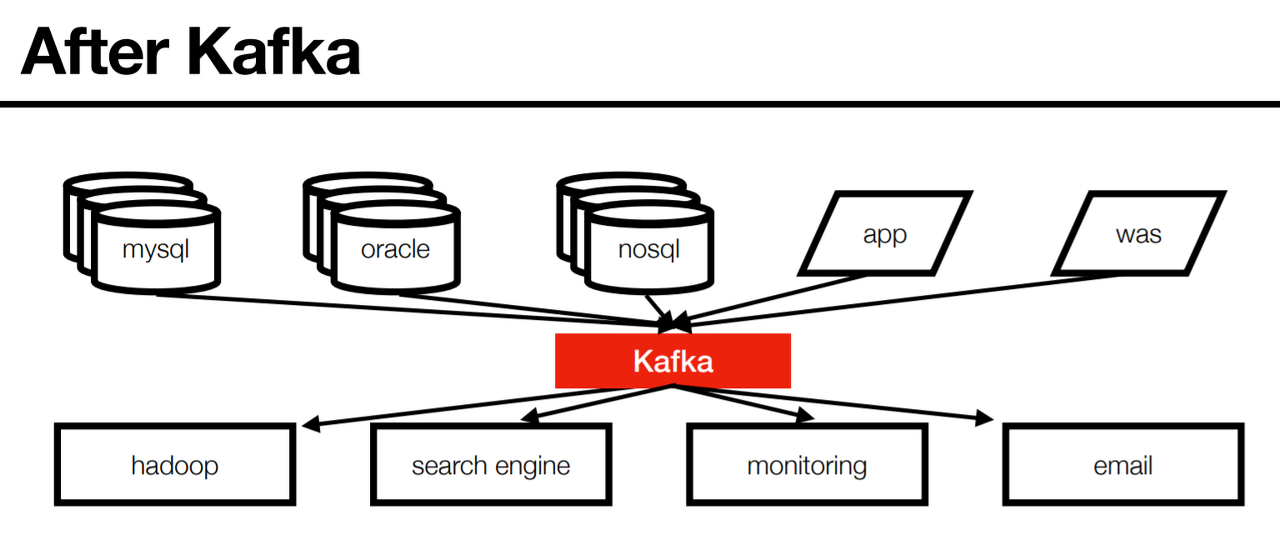
- 프로듀서(Producer) / 컨슈머(Consumer) 분리
- 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 스케일 아웃 기능
- 관련 생태계 제공
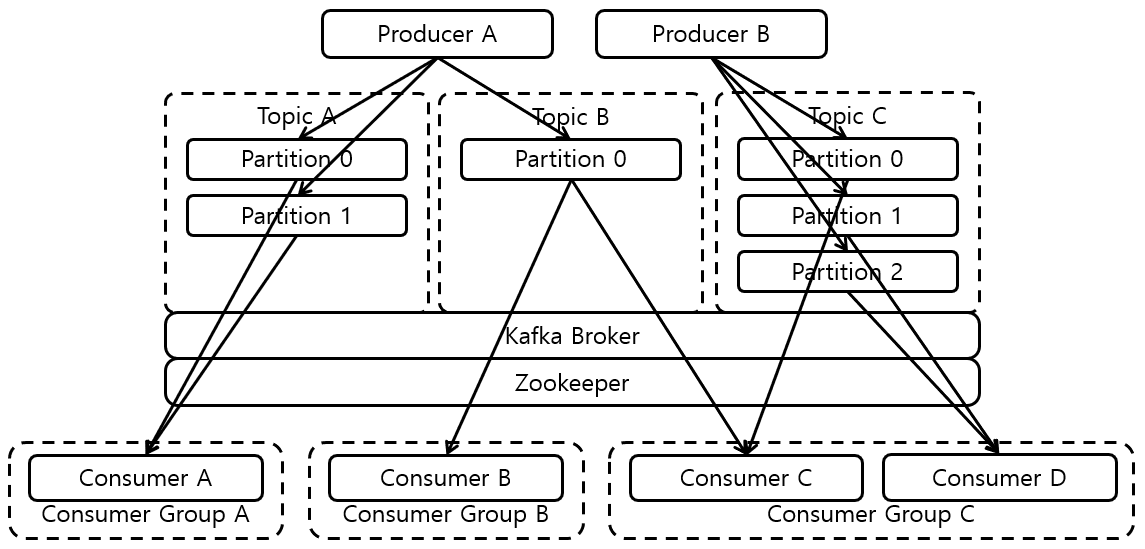
핵심 요소
- Record - byte형태로 직렬화/역직렬화 한 데이터
- Log & Segment - 실제로 메시지가 저장되는 파일시스템 단위
- Broker - 카프카 애플리케이션 서버 단위
- Zookeeper - 메세지 정보 관리
- Replication - 레코드를 브로커로 전송하는 애플리케이션
- ISR - 리더 + 팔로워 파티션의 sync가 된 묶음
- Topic - 데이터 분리 단위
- Partition - 레코드를 담고 있음. 컨슈머 요청 시 레코드 전달
- Offset - 각 레코드 당 파티션에 할당된 고유 번호(index)
- Producer - 레코드를 브로커로 전송하는 애플리케이션
- Consumer - 레코드를 polling하는 애플리케이션
- Consumer Group - 다수 컨슈머 묶음
- Consumer Offset - 특정 컨슈머가 가져간 레코드의 번호
- Rebalancing - 컨슈머에 장애가 생기거나 변화가 생기는 경우 파티션과 컨슈머를 재 할당
Kafka Client
Kafka와 데이터를 주고받기 위해 사용하는 Java Library
프로듀서(Producer), 컨슈머(Consumer), Admin, Stream 등 Kafka관련 api 제공
다양한 3rd party library 존재 : C/C++, Node.js, Python, Net 등
Clients - Apache Kafka - Apache Software Foundation
How The Kafka Project Handles Clients Starting with the 0.8 release we are maintaining all but the jvm client external to the main code base. The reason for this is that it allows a small group of implementers who know the language of that client to quickl
cwiki.apache.org
Kafka broker 버전과 client 버전 하위호환 확인 필요
Kafka broker와 java client의 버젼 하위호환성 정리
하위 호환성은 기술 및 컴퓨터 분야에서 새 제품이 이전 제품을 염두에 두고 만들어진 제품에서 별도의 수정 없이 그대로 쓰일 수 있는 것을 뜻한다. Kafka는 1.XX version으로 올라가기 전까지는 "one
blog.voidmainvoid.net
Kafka Streams
데이터를 변환(Transformation)하기 위한 목적으로 사용하는 API
스트림 프로세싱을 지원하기 위한 다양한 기능을 제공
- Stateful 또는 Stateless와 같이 상태기반 스트림 처리 가능
- Stream api와 DSL(Domain Specific Language)를 동시 지원
- Exactly-once 처리, 고 가용성 특징
- Kafka security(aci, sasl 등) 완벽 지원
- 스트림 처리를 위한 별도 클러스터(ex. yam 등) 불필요
Kafka Connect

많은 경우 Kafka client로 Kafka로 데이터를 넣는 코드를 작성할때도 있지만, Kafka connect를 통해 data를 Import/Export 할 수 있음
코드 없이 configuration으로 데이터를 이동시키는 것이 목적
- Standalone mode, distribution mode 지원
- REST api interface를 통해 제어
- Stream 또는 Batch 형태로 데이터 전송 가능
- 커스텀 connector을 통한 다양한 plugin 제공(File, S3, Hive, Mysql etc...)
Kafka Mirror maker

특정 카프카 클러스터에서 다른 카프카 클러스터로 Topic 및 Record를 복제 하는 Standalone tool
2019년 11월, 기존 MirrorMaker를 개선한 MirrorMaker2.0 release
클러스터간 토픽에 대한 모든 것을 복제하는 것이 목적
- 신규 토픽, 파티션 감지기능 및 토픽 설정 자동 Sync기능
- 양방향 클러스터 토픽 복제
- 미러링 모니터링을 위한 다양한 metric(latency, count 등) 제공
그 외 Kafka 생태계를 지탱하는 application들
- confluent/ksqlDB : sql구문을 통한 stream data processing 지원
- confluent/Schema Registry : avro기반의 스키마 저장소
- confluent/REST Proxy : REST api를 통한 consumer/producer
- linkedin/Kafka burrow : consumer lag 수집 및 분석
- yahoo/CMAK : 카프카 클러스터 매니저
- uber/uReplicator : 카프카 클러스터 간 토픽 복제(전달)
- Spark stream : 다양한 소스(카프카 포함)로 부터 실시간 데이터 처리
- ...