카프카(Kafka)의 기본 개념 - 브로커(Broker)
브로커(Broker)
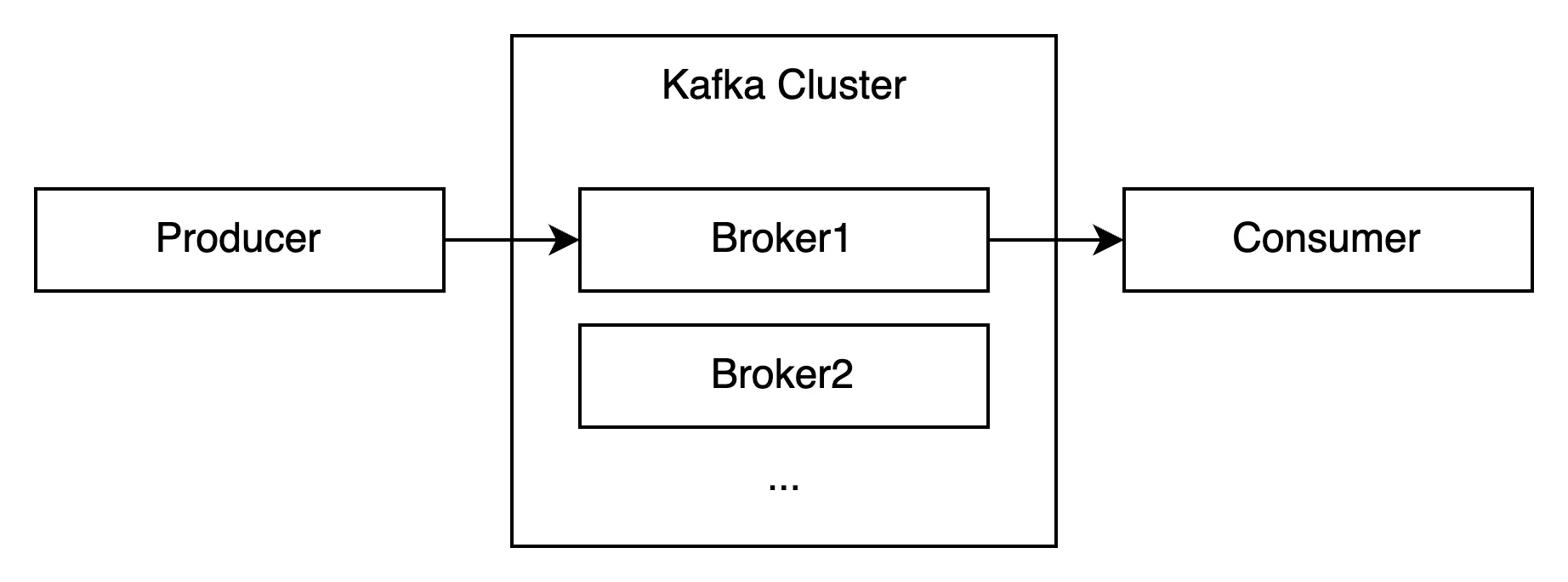
브로커(broker)는 카프카 클러스터(Kafka Cluster)의 구성 요소로, 데이터를 저장하고 프로듀서(Producer)와 컨슈머(Consumer) 간의 통신을 담당합니다. 카프카 클러스터는 여러 브로커로 구성되며 데이터들을 분산 저장하여 안전하게 사용할 수 있습니다.
데이터 저장, 전송
브로커는 프로듀서로부터 데이터를 전달받으면 프로듀서가 요청한 토픽(Topic) 내부에 존재하는 파티션(Partition)에 데이터를 저장하고 컨슈머가 데이터를 요청하면 해당 파티션에 저장된 데이터를 전달합니다.
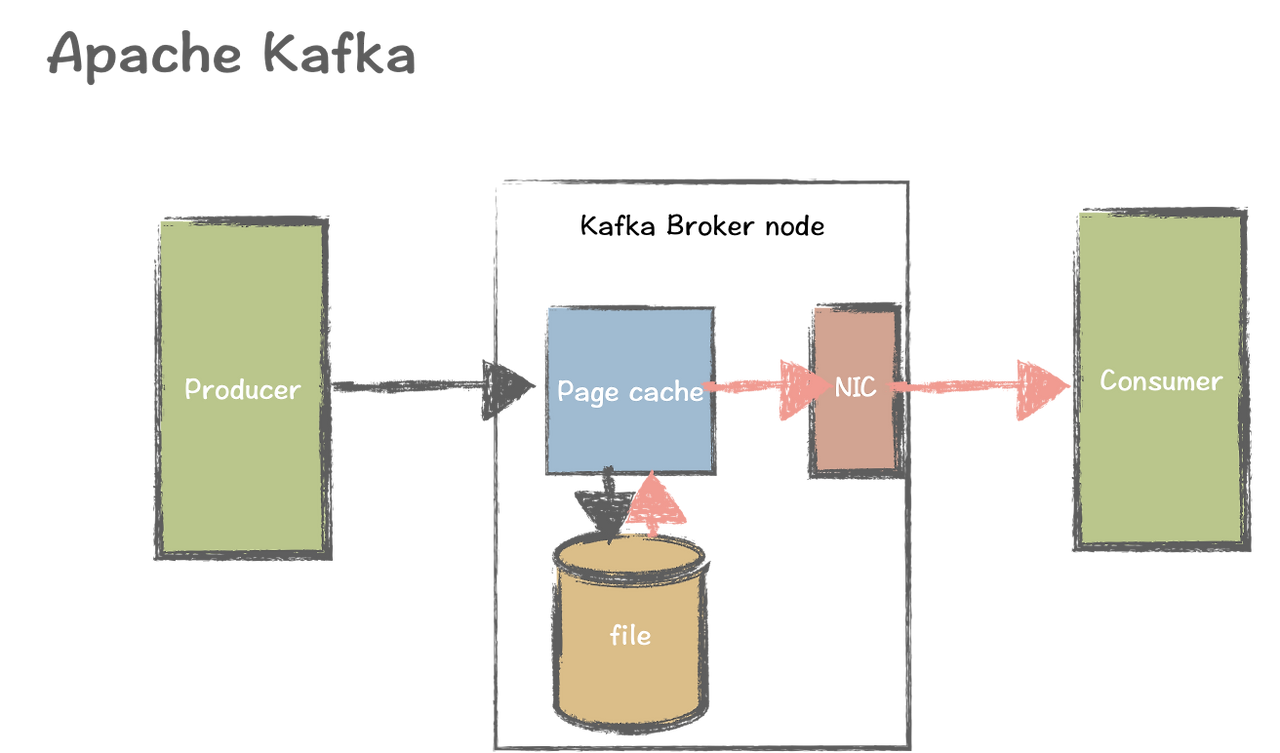
이렇게 전달된 데이터는 파일 시스템에 저장되는데,
파일 시스템은 다루기는 편하지만 입출력이 많아질 경우 메모리에 올려서 사용하는 것보다 처리 속도가 현저히 느려집니다.
카프카는 이러한 문제를 해결하기 위해 페이지 캐시(Page Cache) 메모리 영역을 활용합니다.
사용하여 한번 읽은 파일의 내용을 페이지 캐시 영역에 저장하여 해당 파일에 접근할 경우 디스크에서 읽지 않고 메모리에서 직접 읽어 속도가 빠릅니다.
이러한 특징 때문에 JVM의 heap 메모리 사이즈를 크게 설정할 필요가 없습니다.
데이터 복제, 싱크
데이터 복제의 이유는 클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용하기 위함입니다.
카프카의 데이터 복제는 파티션 단위로 이루어지고 토픽을 생성할 때 파티션의 복제 개수(replication factor)를 설정할 수 있습니다.
만약 설정하지 않는다면 브로커에 설정된 옵션값을 따라갑니다. 복제 개수의 최소값은 1(복제 없음)이고 최댓값은 브로커에 개수입니다.
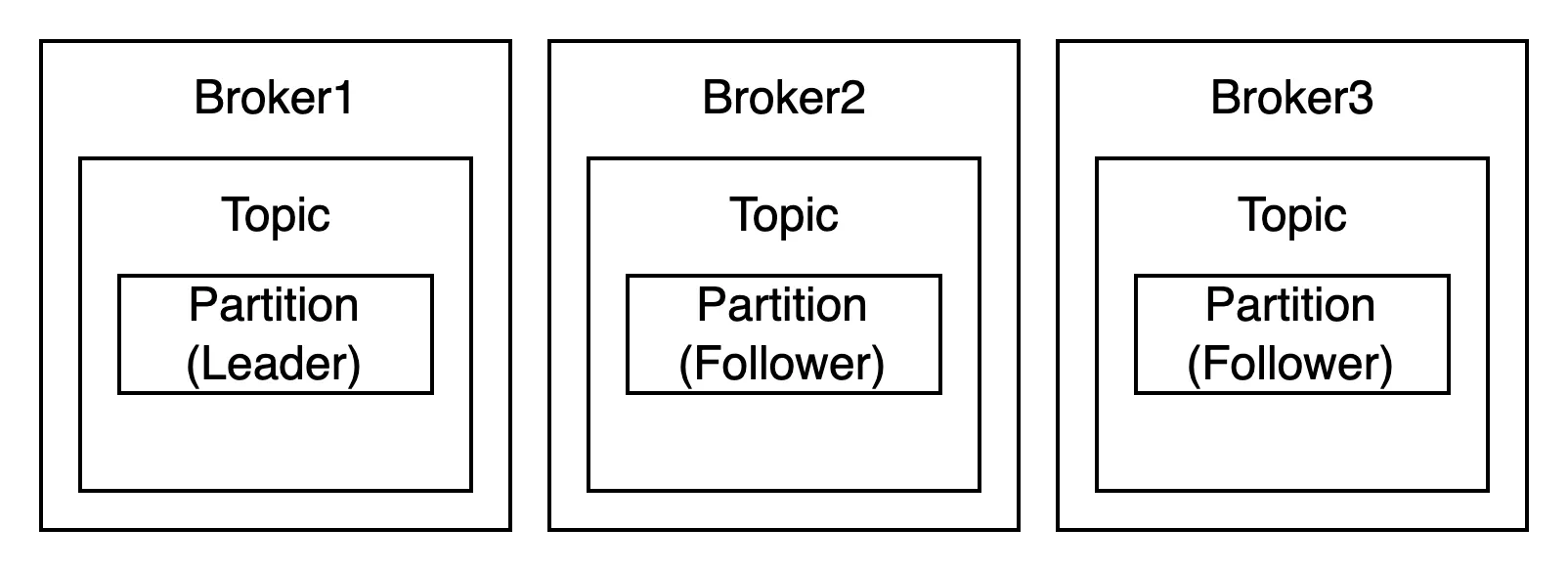
복제된 파티션은 리더(Leader)와 팔로워(Follower)로 구성되는데,
팔로워 파티션들은 리더 파티션의 오프셋을 확인하여 현재 자신이 가지고 있는 오프셋과 차이가 나는 경우 리더 파티션으로부터 데이터를 가져와서 자신의 파티션에 저장합니다.
이를 통해 복제 개수만큼 저장 용량이 증가한다는 단점이 있지만 데이터를 안전하게 사용할 수 있다는 장점 때문에 카프카를 운영할 때는 최소 2 이상의 복제 개수를 설정하는 것을 권장합니다.
만약 Broker1에 장애가 발생해 다운되었다면 해당 브로커에 있는 리더 파티션은 사용할 수 없기 때문에 팔로워 파티션 중 하나가 리더 파티션 지위를 넘겨받습니다. 이를 통해 데이터가 유실되지 않고 데이터를 주고받을 수 있습니다.
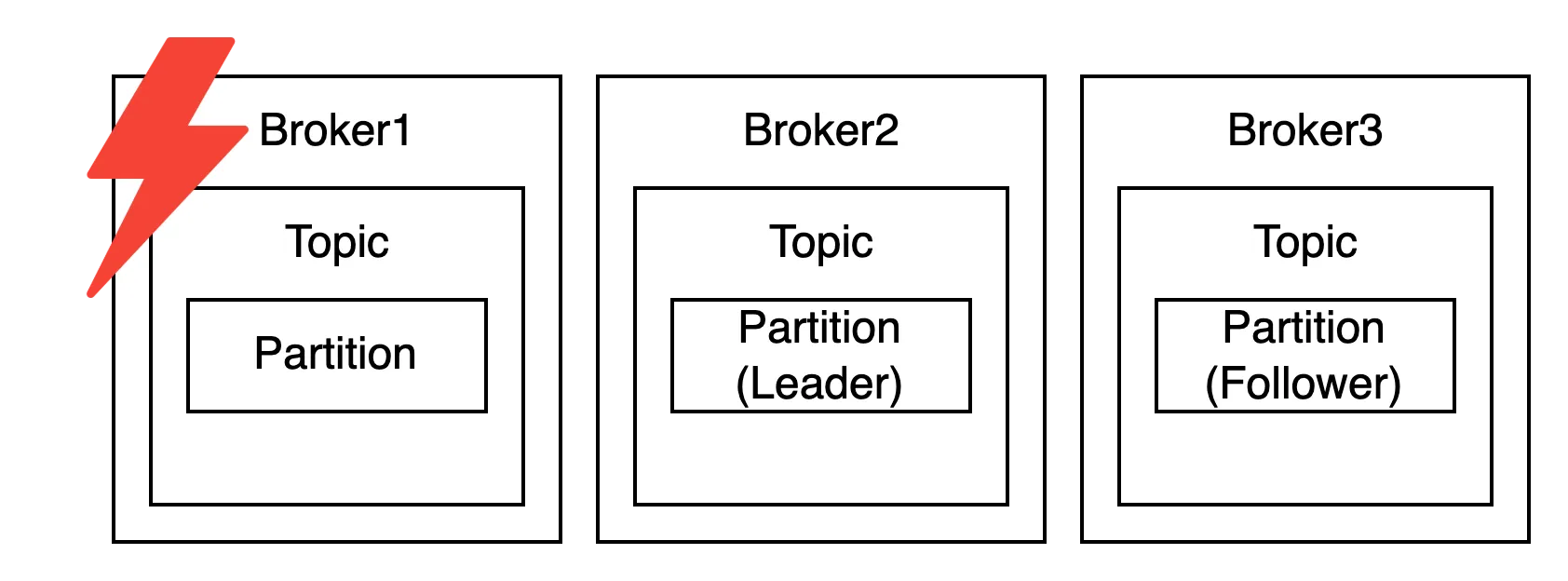
카프카는 지속적으로 데이터를 처리해야 하므로 브로커의 상태가 비정상이라면 빠르게 클러스터에서 빼내는게 중요합니다.
클러스터의 다수 브로커 중 한대가 다른 브로커들의 상태를 체크하고 리더 파티션을 재분배하는 컨트롤러(Contorller) 역할을 합니다.
만약 컨트롤러 브로커에 장애가 생긴다면 다른 브로커가 컨트롤러 역할을 합니다.
데이터 삭제
카프카는 다른 메시징 플랫폼과 다르게 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않고, 프로듀서나 컨슈머가 삭제 요청도 할 수 없습니다.
오직 브로커만이 데이터를 삭제할 수 있는데 로그 세그먼트(log segment)라는 파일 단위로 삭제가 이루어집니다.
세그먼트에는 다수의 데이터가 저장되어 있기 때문에 특정 데이터를 선별하여 삭제할 순 없습니다.
세그먼트는 데이터가 쌓이는 동안 계속해서 열려있으며, 브로커에 log.segment.bytes 또는 log.segment.ms 옵션을 통하여 해당 조건에 도달했을때 세그먼트를 닫을 수 있습니다.
너무 작은 용량으로 설정한다면 파일을 자주 여닫음으로써 부하가 발생할 수 있으므로 주의해야 합니다.
닫힌 세그먼트는 브로커에 log.retention.bytes 또는 log.retention.ms 옵션에 설정값이 넘으면 삭제됩니다.
닫힌 세그먼트 파일을 체크하는 간격은 브로커에 log.retention.check.interval.ms 옵션으로 설정할 수 있습니다.
컨슈머 오프셋 저장
오프셋(Offset)이란 각 파티션마다 데이터가 저장되는 위치를 의미합니다. 이 오프셋을 통해 컨슈머가 데이터를 어디까지 가져갔는지 기억하게 됩니다.
커밋한 오프셋은 __consumer_offsets 토픽에 저장되고, 저장된 오프셋을 기준으로 다음 데이터를 가져가서 처리합니다.
코디네이터(Coordinator)
클러스터의 브로커 중 한 대는 컨트롤러와 마찬가지로 코디네이터(Coordinator)의 역할을 수행하는데,
코디네이터는 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 재할당합니다.
이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스(Rebalance)라고 부릅니다.
다음 글
카프카(Kafka)의 기본 개념 - 토픽(Topic), 파티션(Partition), 레코드(Record)
토픽(Topic)과 파티션(Partition)토픽(Topic)은 카프카에서 데이터를 구분하기 위해 사용하는 단위입니다.토픽은 1개 이상의 파티션(Partition)을 소유하고 있고 파티션에는 프로듀서가 보낸 데이터들이
devbksheen.tistory.com